🚀 Supercharge your YouTube channel's growth with AI.
Try YTGrowAI FreeWeb Scraping with Curl Commands in Python 3

The curl command is used in many scripts written in Python language. Sometimes, we need all available data from the web to train our models. This process of collecting the data is known as web scraping. We can execute the web scraping using this curl command in Python3. The curl command in Python3 is considered as a command-line tool. The command-line tools are single-line utilities developed to solve specific problems. The curl command carries out the job of sharing information across the web/network. We can see some details of the curl command in this article.
Understanding the Curl Command in Python 3
The curl command is the cURL (Client URL) that helps to collect large amounts of information across the web/network. PycURL library is mainly used in Python language to execute the curl commands in Python code. This curl command is very adaptive and carries out different functions like handling HTTP requests and REST API calls for different operating systems. It is a low-level command line tool that helps in web scraping.
To execute this command properly in Python3, we need some packages. The first thing we should have is a ‘pip’. The pip is a package management system that helps to download various libraries.
How to Install and Check Pip Version in Python 3
If you already have ‘pip’ installed in your system, then the version of pip will be displayed using this command: pip –version. Otherwise, the output will be: ‘pip –version’ is not recognized as an internal or external command, operable program or batch file. This ‘pip’ command will help us to install packages to execute the scripts in Python3.

Essential Python Packages for Curl Operations
Python provides very specific packages to operate the curl command. These packages are PycURL, subprocess, and certify. The PycURL is the main library that is used to execute the curl command in Python3.
Along with this, the certifi package is used to validate the websites. One more package of Python3 is available to execute the curl command which is a subprocess. Let’s see the installation and some details related to these libraries.
Installing the PycURL Package
The libcurl is a multiprotocol library mainly used to process client-side requests. This PycURL package is nothing but the Python interface of this libcurl, which is used to process client-side requests. This package is validated for specific Python versions ranging from Python 3.5 to Python 3.10.
To install this package in Python we can use the ‘pip install pycurl’ command. The PycURL package helps to set the data requests across the networks.
This package will also help to test different API’s and downloading files. We will see the examples based on get request, post request, and web scraping using the PycURL package, which will execute the curl command.

Installing the Certifi Package for Secure Connections
When we try to fetch any information from specific websites, we need to ensure security. The SSL certificate provides digital authentication for various websites. SSL is an acronym for Secure Socket Layer. This package will help to ensure the security of the overall process. This package can installed using the ‘pip install certifi‘ command.

Installing the Subprocess Package for Command Execution
The subprocess package in Python3 will help to execute the external command/code along with the ongoing code. The call() function from the subprocess module will help to execute the code. It allows the communication between the parent process and the child process. This package will help to execute the curl command. This package can installed using the ‘pip install subprocess.run‘ command.

Practical Examples: Using Curl Commands in Python 3
There are different examples where we can execute the curl command using packages/libraries of Python3. The first one we are going to implement is ‘Get Request’. This type of request establishes the connection with the HTTP server to get resources for our model. For this process, we need a connection between a web page and cURL. The data/ resources can be accepted in any format under this command.
Example 1: GET Request Using Curl Command
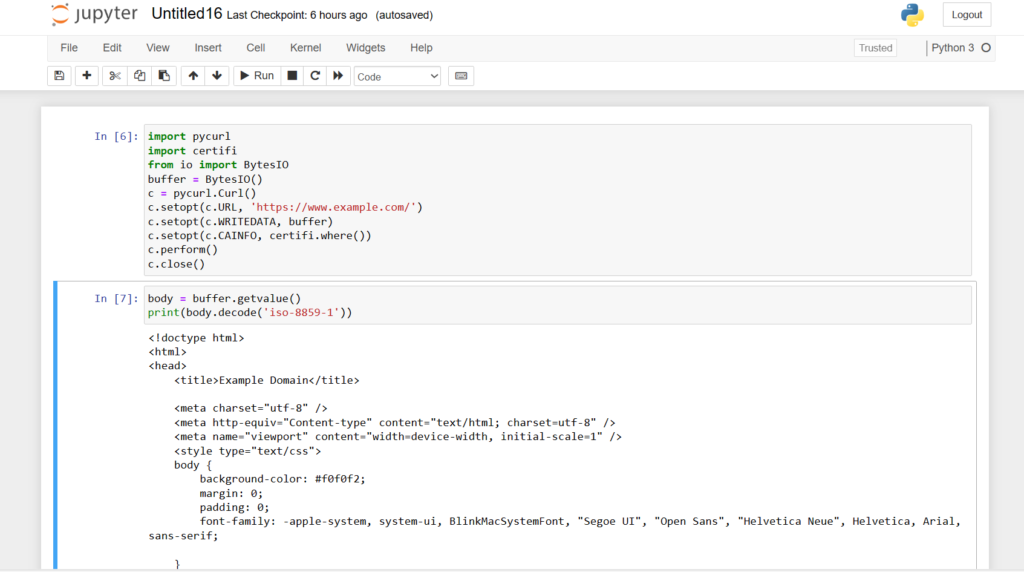
import pycurl
import certifi
from io import BytesIO
buffer = BytesIO()
c = pycurl.Curl()
c.setopt(c.url, 'https://www.example.com/')
c.setopt(c.WRITEDATA, buffer)
c.setopt(c.CAINFO, certifi.where())
c.perform()
c.close()
In this section of code, we are creating a buffer. We have one website that is used as an example. We are providing the URL of that website here. We are trying to establish a connection between the web page and the server. The certificates of the web page will be verified by the certifi package. The resources are encoded, so we need to decode the content in the next section of the code.
body = buffer.getvalue()
print(body.decode('utf-8'))
Run this code, and we will get the required results.
Example 2: POST Request Using Curl Command
The POST request can be done using a single line command tool, i.e. curl command. You can run a single bash command to implement this code. The simple syntax of this code involves the curl keyword followed by -d and -request_type(here, we are using POST). In this example, we are testing our code using an example site. The simple curl command will help to set the HTTP server for POST operation. In this example, we have used the subprocess library.
import subprocess
curl_command = [
'curl',
'-X',
'POST',
'-H',
'Content-Type: application/json',
'-d',
'{"key1": "value1", "key2": "value2"}',
'https://example.com/api'
]
result = subprocess.run(curl_command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
if result.returncode == 0:
print("Curl Output:")
print(result.stdout)
else:
print("Error:")
print(result.stderr)
The single line code for the POST request can be implemented on the terminal to find out the output of a specific URL.
curl -X POST -H "Content-Type: application/json" -d '{"key1": "value1", "key2": "value2"}' https://example.com/api

Example 3: Searching for Responses Using Curl Command
The subprocess and requests library can be used to process this code. The data from the requested URL can be searched using the required parameters provided in the code. This curl command makes everything easy and simple to process the search requests.
import subprocess
import requests
search_url = "https://www.example.com/"
search_params = {
"q": "your_search_query",
"parameters": "additional_parameters"
}
query_string = "&".join([f"{key}={value}" for key, value in search_params.items()])
full_url = f"{search_url}?{query_string}"
curl_command = ["curl", full_url]
output = subprocess.check_output(curl_command, text=True)
print(output)
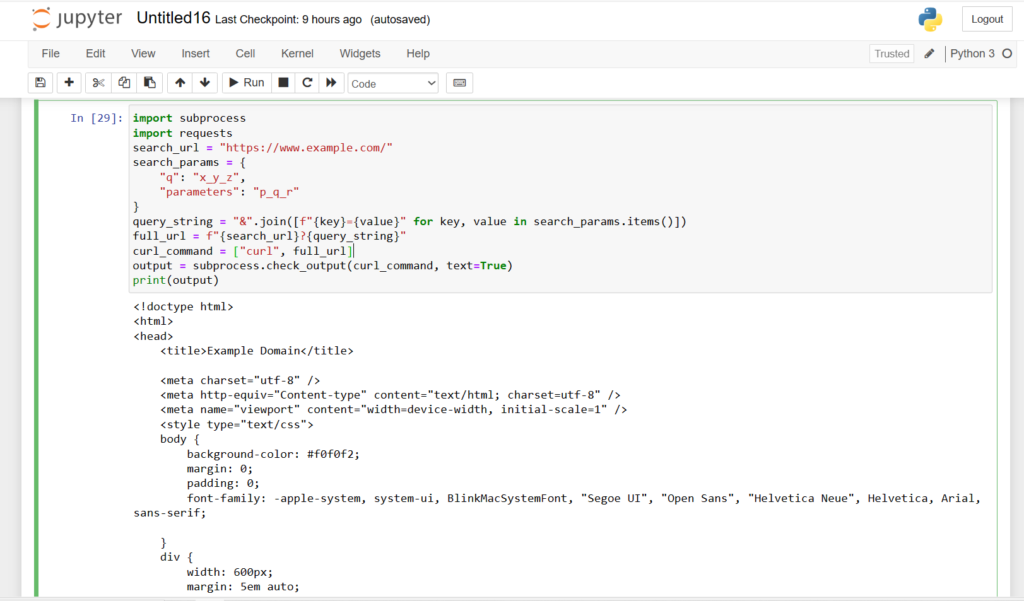
The data can be sorted according to our parameters. In the place of x_y_z and p_q_r, we can provide our own parameters.
Example 4: Web Scraping with Curl Command
Sometimes, we need large datasets to train the machine learning and data analysis models. These datasets contain information on a large scale. In some cases, this data is available on web pages, For example, the dataset of images. In this case, the data is available on the particular web page where we need to extract the 500-600 images at the same time. Here, we can use web scraping. Web scraping techniques will help to collect large amounts of data.
import pycurl
import certifi
from io import BytesIO
URL = 'http://www.iana.org/help/example-domains'
buffer = BytesIO()
curl = pycurl.Curl()
curl.setopt(curl.URL, URL)
curl.setopt(curl.WRITEDATA, buffer)
curl.setopt(curl.CAINFO, certifi.where())
curl.perform()
curl.close()
body = buffer.getvalue()
data = body.decode('iso-8859-1')
print(data)
In this example, we are implementing the web scraping using PycURL and the certifi package. The data from the particular URL is collected using these libraries in a few seconds. We have created a buffer to store the data, and later, it will decoded to the original form and printed in the end.

Using this code, we can scrap entire data from any URL.
Example 5: Curl Command Using Subprocess Module
In this method, we will skip the shell attribute of the run() function from the subprocess module. Instead of a shell command, we will try to add another list of arguments. This method is preferable because it will reduce the harm of shell injection vulnerabilities. Let’s execute the code.
import subprocess
def execute_curl_command(curl_args):
try:
result = subprocess.run(["curl"] + curl_args, capture_output=True, text=True)
print("Curl output:")
print(result.stdout)
return result.stdout, result.returncode
except subprocess.CalledProcessError as e:
print("Error executing curl command:", e)
return None, e.returncode
curl_args = ["https://api.example.com/data"]
output, return_code = execute_curl_command(curl_args)
This example uses different arguments that help to execute this curl command in Python language. A simple error message will displayed if there is any error in the code. Otherwise, the output of the code will be printed. Let’s see the results.
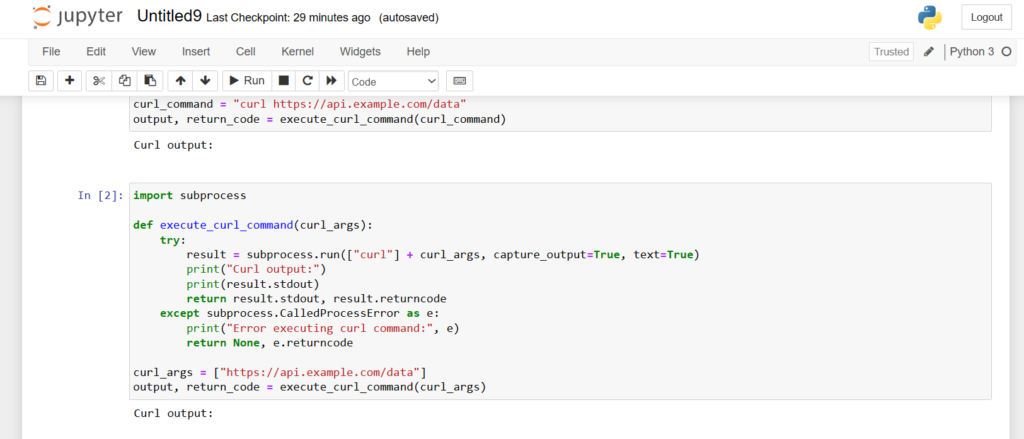
The output is printed without any error message. So, you can insert your URL and implement the same code to get results.
Wrapping Up
In this article, we have explained the examples, applications, and basics of the curl command in Python3. The curl command can be implemented using packages like PycURL, subprocess, certifi, requests, etc.
There is a wide range of applications of curl command in Python3. These applications are explained as an example in this article, for example, implementation of GET request, POST request, SEARCH request, web scraping, etc.
We’ve delved into the various applications of the curl command in Python 3 From web scraping to API testing, curl offers a range of functionalities. What will you scrape next?
References
Do read the official documentation on the subprocess module, Stack Overflow Query, SQL Docs



