🚀 Supercharge your YouTube channel's growth with AI.
Try YTGrowAI FreeHow to Load Pickled Pandas Object From a File as a Path?

Pickle is the binary storage format that is used for object serialization. The process of converting python objects into byte streams is called serialization.
Simply put, a byte stream is a sequence of bytes, a more straightforward method to store binary data. Since pickled data is a binary data format, it can be converted into a byte stream.
When the data is converted into a byte stream, it allows the data to be saved on the disk, and these bytes can be transmitted over a network.
Likewise, pickle is also used to deserialize an object from a byte stream.
The read_pickle of the Pandas library is used to read a pickled object.
Check this out to learn more about How to Read Pickle Files in Pandas?
Why Should We Pickle an Object?
You might hear about reading a file or any data using CSV format. But pickle is a less-known and lighter data format for big data analytics.
Pickling an object helps store the data on the disk. When the data is stored on the disk, it will be easy to bring it to the required environment quickly. Storing the data on the disk will also help in deserializing the object.
There is one more advantage of pickling an object. The type() of the object is preserved when it is pickled. This may not be the case using other file formats such as CSV.
Which File Format Should You Choose For Your Next Project, Pickle or CSV?
While the CSV file format allows you to modify data on-the-fly, it also takes up more disk space.
Let us take a quick go-through between reading data using pickle and CSV.
| CSV | Pickle |
| A CSV data format takes up more space on the disk | A pickle is a lighter data format; it takes up less storage on the disk |
| It is human-readable | Since a pickle is encoded, it cannot be understood by humans before processing |
| A CSV format may not be able to preserve the metadata of the object | Preserves the data types of the object |
| Reading or writing a CSV file is a slower process | Comparatively faster |
Pickled Files May Also Be Harmful
Since the module is not secure, we must be cautious while working with pickle files. We may come across malicious pickle data, which is quite dangerous. Therefore we need to be careful with downloading any data from a source.
Exploring read_pickle Syntax
By default, the Pandas library provides for reading and writing pickle data.
The syntax is given below :
pandas.read_pickle(filepath_or_buffer, compression='infer', storage_options=None)
The description of the parameters is given below.
| Argument | Description | Default value | Requirability |
| file_path or buffer | The file path must be a string or file-like object | str | Required |
| compression | The type of compression we use is important while pickling. Because when we want to deserialize the data, the same compression mode should be used for error-free retrieval The default compression mode is ‘infer’ If the compression is ‘infer’ and the string to be pickled is a path, the extension can be any of the following: .gz’, ‘.bz2’, ‘.zip’, ‘.xz’, ‘.zst’, ‘.tar’, ‘.tar.gz’, ‘.tar.xz’ or ‘.tar.bz2’ For example, if the file path is pckl.pkl while reading, for deserializing, the path should be pckl.bz2 or pckl.zipOne thing to remember while using the .zip or .tar extension is that the zip file must contain only one data file to be read. Multiple files in ZIP may not be supported. If decompression is not required, None is used The data to be pickled can also be a dictionary If this dictionary has a key ‘method,’ then the compression extension would be: {‘zip’, ‘gzip’, ‘bz2’, ‘zstd’, ‘tar’} All the other key-value pairs are compressed using. zipfile.ZipFile, gzip.GzipFile, bz2.BZ2File, zstandard.ZstdDecompressor or tarfile.TarFile extensions | Type: str or dict Default: infer | Required |
| storage_options | These are the extra parameters that are forwarded for storage connection like host, port, username, and password The storage_options is a dictionary that contains the following keys: compression, mode, engine,storage_class If the URL is HTTP(s), the key-value pairs of the above dictionary are forwarded to urllib.request.Request as headerIf the URL is something like “s3://” or “gs://”, the key-value pairs are forwarded to fsspec.open | dict | Optional |
read_pickleReturn type:
unpickled Returns the same type as the object stored in the file.
Example 1:Loading a Pickled Dataset
Let us consider a TPS June competition pickle dataset.
The TPS stands for Tabular Playground Series, a beginner-friendly competition of Kaggle for creating the best datasets that can be used for different machine learning models.
This dataset is a sample of the submissions for the above purpose.
We need to copy the file path to the read_pickle.
The code is given below.
import pandas as pd
pickl=pd.read_pickle('data.pkl')
print(pickl.size)
print("*"*15)
print(pickl)
Here is a quick explanation of the code.
import pandas as pd: We are importing or bringing the Pandas library to our IDE, which is necessary to read or write any data. We are also giving it an alias name, ‘pd’, a standard short name for this library.
pickl=pd.read_pickle(‘data.pkl’): The file path-data.pkl is read using the read_pickle function, and this path is stored in a variable called pickl.
print(pickl.size): Suppose you want to know the size of this file. We can know the size of the file using the print() with the filename followed by size- pickl.size in this case.
print(“*”*15): This line is used for beautification. The code outputs 15 asterisks(*) to the screen.
print(pickl): We print the data in the file using the print function.
This data is stored in the local disk but may not be supported due to encoding.
The output is given below.
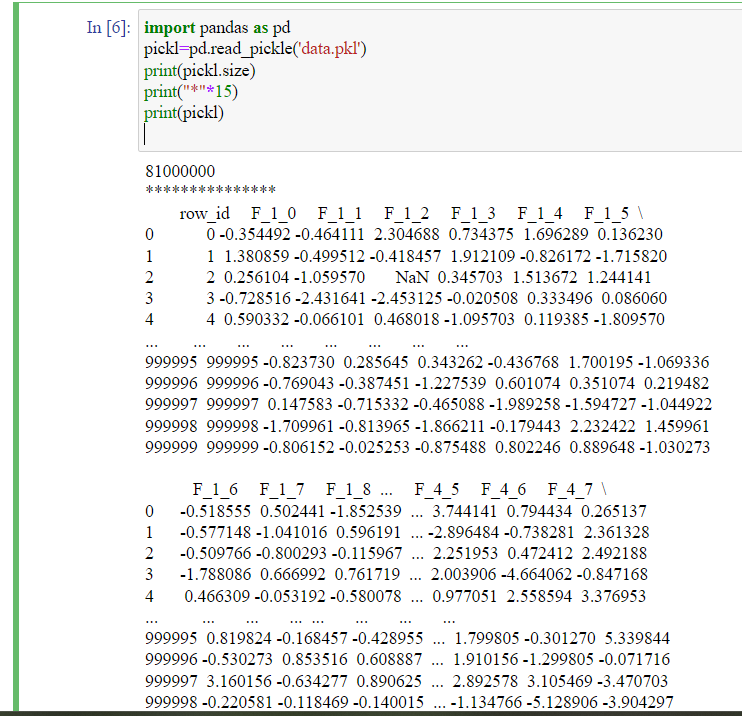
As observed from the output, the size of the dataset is huge.
It has some 100000 rows of data. But with reading in a pickle format, it just took less than a few seconds.
The %timeit is a python module that measures the execution time of one-line codes. The illustration of calculating the time taken to read a pickle file using the module is given below.

The To_pickle() Method
In the upcoming examples, we will see the usage of to_pickle(), also provided by Pandas library, which converts a data frame to a pickle file.
Also read: Pandas to_pickle(): Pickle (serialize) object to File
Example 2:Passing an Excel File as a Path
This excel file is a collection of entries of name, id, and gender of people from different countries.
The size of this excel file is 100 rows.
Before we pass the excel file to the read_pickle, we should first read the file using read_excel to make it compatible.
The code is shown below.
import pandas as pd
df=pd.read_excel('example.xlsx')
df.to_pickle('example.pkl')
pckl=pd.read_pickle('example.pkl')
print(pckl)
print(type(pckl))
The above code imports the Pandas library in the first line – import pandas as pd
read_excel: We create a data frame(df) which is used to store the excel file that is read by read_excel.
df.to_pickle: Since the data is in excel format, first, we need to convert it to pickle format, which is done by to_pickle. The new pickle file is stored in ‘example’ with the ‘pkl’ extension.
In the following line, we read the new pickle file and store it in a new variable called pckl.
In the following line, we print the data stored in the pckl variable.
We can also print the data type using the type() function.
The output of the above line would be a data frame.

Example 3:Passing a Data Frame as a File Path
In this example, let us see the creation of a data frame and passing it to the read_pickle as a file path.
We can create a data frame with the help of a dictionary, as shown below.
import pandas as pd
# creating a dict
details = {
'Name' : ['John', 'Doe', 'Alyssa', 'Steve','Jordan','Jake','Jay'],
'Age' : [23, 21, 22, 21,20,23,21],
'University' : ['Cambridge','Boston','Cambridge','NYE','Boston','NU','NYE'],
'ID':[601,802,614,971,812,319,987]
}
# creating a Dataframe object
df = pd.DataFrame(details)
print(df)
print('-'*25)
df.to_pickle('example1.pkl')
pickld=pd.read_pickle('example1.pkl')
print(pickld)
print(type(pickld))
Let us see a quick explanation of the code.
We are importing the Pandas library in line 1.
In line 3, we create a dictionary that is stored in the variable details.
df=pd.DataFrame(details): The data is stored in a key-value pair in a dictionary. A dictionary can be converted into a data frame with the help of pd.DataFrame. The resulting data frame is stored in df shown in line 10.
Line 11 shows how we can print the data frame to the screen.
The following line of code is used as a separator since there are two similar outputs. This line outputs 25 hyphens(-) to the screen.
The data frame can be converted to a pickle format using the to_pickle function as shown in line 13. The pickle file is stored in a variable called example1 with a pkl extension.
Now, this pickle file can be read using the read_pickle and is stored in another variable called pickld.
Finally, in line 14, we print the data using the print().
We can check the type of data using the type(). In this example, the type is a data frame.
The data frame is given below.

Example 4:Reading a CSV File
In this example, let us pass a CSV file as input to the function.
This CSV file contains related information of 5172 randomly picked email files and their respective labels for spam or not-spam classification.
First, let us see how to read a CSV file.
import pandas as pd
df=pd.read_csv('emails.csv')
#first five rows of the data
print(df.head())
print('-'*30)
Starting with line 1, the Pandas library is imported into the environment.
pd.read_csv: We can read the CSV file with the help of read_csv. This data is stored in a variable called df.
df.head()– This function is used to print the first five entries of the data frame. The default function prints five entries, but you can specify the number of the first few rows you wish to be printed.
Example- df.head(2), df.head(10) and so on.
In the next line, we are creating a separator. This line outputs 30 hyphens(-) to the screen.

We pass the obtained data frame as input to to_pickle and read the pickled format.
The code is supposed to look like this.
#pickling
df.to_pickle('emails.pkl')
#reading the pickled file
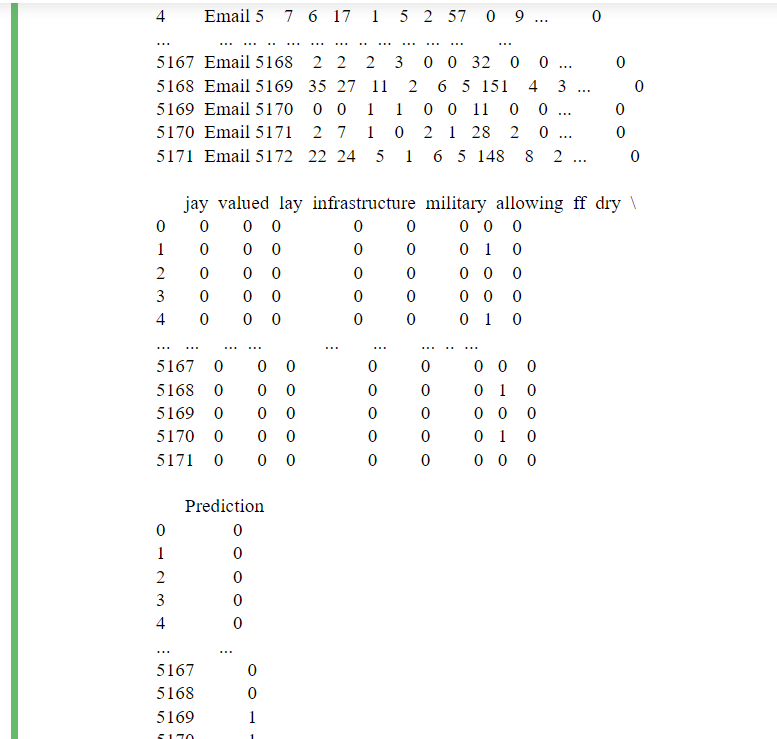
email_pkl=pd.read_pickle('emails.pkl')
#DataFrame
print(email_pkl)
df.to_pickle: The obtained data frame is converted to a pickle file with the help of to_pickle. This pickle file is stored in ’emails.pkl’.
In line four, the pickle file is being read and is stored in the variable-’email_pkl’.
Finally, in line six, we print the data residing in ’email_pkl’.
Conclusion
To summarize, pickle is a binary data format used in big data analytics, enabling us to serialize any object. The serialization process involves converting data into a sequence of bytes, which is easy to store on the disk and can be transmitted over a network.
The read_pickle function is used to read the pickle data in Python. The syntax for the same is provided and the arguments have also been explained.
In the first example, we have seen how to load a pickled dataset as a file and pass it to the function as an argument. We have also seen the usage of %timeit to calculate the time taken to complete this task.
We have also seen the conversion of various file formats(excel, CSV) into the pickle format using the to_pickle function, and reading them as a pickle with the help of read_pickle function.
We have seen how the data is stored in a dictionary and how we can convert it to a data frame which is then passed as an argument to the read_pickle function.
Datasets
TPS June dataset:
https://www.kaggle.com/datasets/lonnieqin/tps-june-pickle-dataset?select=data.pkl
The dummy excel dataset:
Email classification dataset:
https://www.kaggle.com/datasets/balaka18/email-spam-classification-dataset-csv
References
Also, check out the official Pandas documentation
Refer to this stack overflow question on Compression
https://stackoverflow.com/questions/41938552/getting-a-eof-error-when-calling-pd-read-pickle



