🚀 Supercharge your YouTube channel's growth with AI.
Try YTGrowAI FreePandas sort_index() function

Pandas is a Python library, mostly used for data analysis. Pandas make it easier to import, clean, explore, manipulate and analyze data. In this tutorial, we are going to learn about the sort_index() function available in Pandas.
Syntax of the sort_index() function
DataFrame.sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, ignore_index=False, key=None)
| Parameter | Description | Possible Value(s) | Default Value |
| axis | Sort by the axis along which you want to sort. | 0 / ‘index’, 1 / ‘columns’ | 0 |
| level | Reference the level by which dataframe is to be sorted. If not None, sort on values in specified index level(s). | int or level name or list of ints or list of level names | NA |
| ascending | Sort in ascending or descending order. | bool or list of bools: ‘True’, ‘False’ | True |
| inplace | Modify the existing dataframe or create a new one. | bool: ‘True’, ‘False’ | False |
| kind | Kind of sorting algorithm to be applied. | ‘quiksort’, ‘mergesort’, ‘heapsort’, ‘stable’ | quicksort |
| na_position | The position where to put the NaNs. | ‘first’, ‘last’ | last |
| sort_remaining | Specify if the dataframe is to be sorted by other levels after sorting by the specified level. | bool: ‘True’, ‘False’ | True |
| ignore_index | If True, the resulting axis will be labelled 0, 1, …, n – 1. | bool: ‘True’, ‘False’ | False |
| key | Specify if the dataframe is to be sorted on the basis of some custom key | Any custom key defined by the user | NA |
Returns: A sorted object i.e. dataframe. If inplace=True, the original dataframe itself is sorted, else the user has to specify a new dataframe for storing the result. If no new dataframe is assigned and inplace=False, then None is returned.
This function works for both numeric as well as non-numeric index values.
Creating a dataframe
Let’s begin with creating a dataframe before we jump to the examples here. This will help us work on a dataframe and understand the implementation of the Python sort_index() function.
import pandas as pd
import numpy as np
data = {
'Emp_Name' : ["Anna", "Jeremy", "Dennis", "Courtney",
"Bob", "Ronald"],
'Dept' : ["Operations", "Technology", "Design", "Administration",
"Operations", "Technology"],
'YOE' : [12, 5, 6, 20, 8, 4]
}
Emp_Id = [4, 3, 6, 7, 1, 2]
emp_data = pd.DataFrame(data, index=Emp_Id)
emp_data
Output:

This is a dataframe for storing the information of a company’s employees. It consists of the employee name (Emp_Name), the department in which they work (Dept) and their years of experience (YOE). The data is arranged on the basis of the employee Id (Emp_Id) as specified in the above code.
Examples
Let’s get right into the examples to understand how the sort_index() function is implemented and how it works.
1. Sort in ascending order of the index
# by default, axis=0 so sorting is done by row
emp_data2 = emp_data.sort_index()
emp_data2
Output:

In the above example, we have created a new dataframe named ’emp_data2′ and sorted it basis the index i.e. ‘Emp_Id’ in ascending order. As a result, we got the above dataframe shown in the figure.
2. Sort in descending order of the index
# by default, axis=0 so sorting is done by row
emp_data2.sort_index(ascending=False, inplace=True)
emp_data2
Output:

Here, we have sorted the dataframe in descending order by specifying ascending=False in the code. As specified, inplace=True and as we have not assigned any new dataframe to the function, emp_data2 is sorted ‘inplace‘.
3. Sort on the basis of column labels in ascending order
# axis=1 implies sort by column
emp_data3 = emp_data.sort_index(axis=1)
emp_data3
Output:

In this case, we have a resulting dataframe called ’emp_data3′ in which the column labels are sorted in ascending i.e. lexicographical order. The lexicographic order of the column labels ‘Emp_Name’, ‘Dept’ and ‘YOE’ is ‘Dept’, ‘Emp_Name’, and ‘YOE’, hence the columns are now arranged in this order.
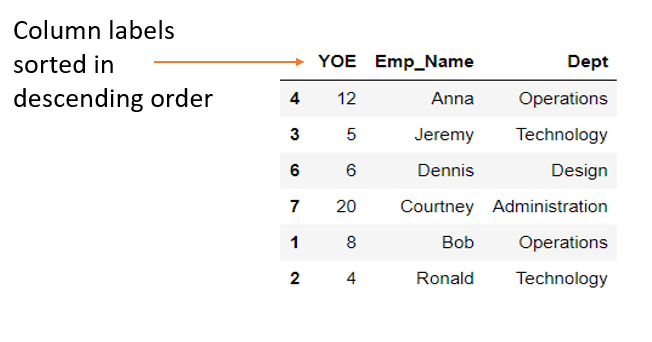
Similarly, we can sort the dataframe in descending order basis the column labels by writing emp_data.sort_index(axis=1, ascending=False). This will result in the below dataframe.
4. Positioning NaNs using the na_position parameter
Let’s consider a slightly modified version of the previous employee dataframe as shown below.
import pandas as pd
import numpy as np
data = {
'Emp_Name' : ["Anna", "Jeremy", "Dennis", "Courtney",
"Bob", "Ronald"],
'Dept' : ["Operations", "Technology", "Design", "Administration",
"Operations", "Technology"],
'YOE' : [12, 5, 6, 20, 8, 4]
}
Emp_Id = [4, np.nan, 6, np.nan, 1, 2]
emp_df = pd.DataFrame(data, index=Emp_Id)
emp_df

The above dataframe has some NaN values in the index i.e. Emp_Id. Let us see how to position these values.
a. Positioning NaNs first
emp_df2 = emp_df.sort_index(na_position='first')
emp_df2
Output:

Here, the dataframe is sorted on the basis of its index i.e. Emp_Id and the NaN values are placed first in the resulting dataframe.
Also read: How to replace NaN values in a Pandas dataframe with 0?
b. Positioning NaNs last
emp_df3 = emp_df.sort_index(na_position='last')
emp_df3
Output:

In this example, the dataframe is sorted on the basis of its index i.e. Emp_Id and the NaN values are placed last in the resulting dataframe.
Conclusion
That’s all in this tutorial! We have learnt about the sort_index() function in Pandas. You can learn more about Pandas by following our tutorials here.
Reference



