🚀 Supercharge your YouTube channel's growth with AI.
Try YTGrowAI FreePython wide_to_long – Unpivot a Pandas DataFrame

In this article let us try to understand the Python wide_to_long() function of the Pandas package. The Pandas package is an excellent tool for working on massive datasets which complex values and statistical tables. This package is free to use and open source, hence is favored by data scientists and data analysts. Pandas stand for “Panel Data” as well as “Python Data Analysis“.
Working with large datasets is not an easy job, to make efficient use of the data one needs to reshape the data in a convenient way. The function discussed in this article is one of the easy ways to unpivot a DataFrame from wide format to long format. Let’s take a look and try to comprehend the use of this function, its syntax, and its implementation in Python programming language.
Why is Python wide_to_long() used?
In the simplest words wide_to_long() function of the Pandas package is used to convert the provided dataframe from ‘wide’ which is many columns format to ‘long’ which is many rows format. This function intends to locate one or more groups of columns with the formats A-suffix1, A-suffix2,…, and B-suffix1, B-suffix2,… with stubnames [‘A’, ‘B’]. In the resulting long format, you can add ‘j’ to designate what you wish to label this suffix (for instance, j=’year’).
These wide variables are considered to have ‘i’ as a unique identifier for each row (can be a single column name or a list of column names)
This function is very similar to the melt() function of the Pandas package, but it is hard-coded to “perform the right thing” in most situations.
Syntax of Python wide_to_long
pandas.wide_to_long(df, stubnames, i, j, sep='', suffix='\\d+')
- df: DataFrame, required
- Dataframe that has to be modified
- stubnames: string or list-like, required
- It is expected that the wide format variables will begin with the stub names.
- i: string or list-like, required
- The column/s to be used as the id value/s
- j: string, required
- The sub-observation variable’s name. It is what you want your suffix to be called in the extended form.
- sep: string, default “”, optional
- a character designating how the variable names in wide format will be separated from the ones in long format. You can remove the hyphen, for instance, if your column names are A-suffix1, and A-suffix2, by providing sep=’-‘.
- suffix: string, default is set to ‘\d+’, optional
- the desired suffixes are captured by a regular expression. “d+” captures suffixes with numbers. The negated character type “D+” can be used to specify suffixes without any numbers. In order to further clarify suffixes, you can specify suffix='(!?one|two)’. For instance, if your broad variables are of the pattern A-one, B-two, etc. and you have an unrelated column A-rating, you can disregard the last one. All suffixes that contain numbers are transformed to int64 or float64.
Implementing the wide_to_long() function in Python
Before we begin with the implementation of the function, please make sure to install and then import the Pandas package into your current IDE. Use the following line of code to import and rename the Pandas package in your IDE.
import pandas as pd
Example 1: Passing only the required parameters
The given below DataFrame is passed as a parameter for the Python wide_to_long function.
df = pd.DataFrame({"car_names": ['Suzuki','Honda','Toyota'],
"fuel_type": ['diesel','petrol','diesel'],
"jan23": [342, 432, 123],
"jan22": [245, 543, 334],
"jan21": [544, 209, 324]})
print(df)
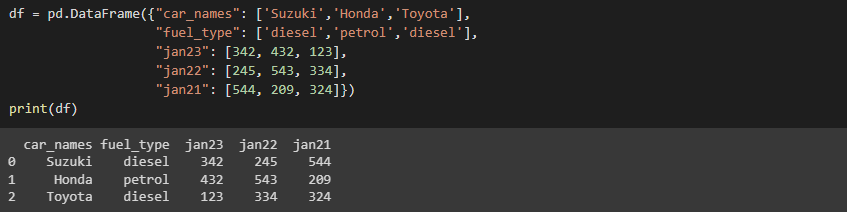
In the following example, the ‘stubnames’ parameter is set to ‘jan’ as the wide variable columns start with it. and the ‘i’ parameter indicates the id_variable.
pd.wide_to_long(df, stubnames='jan', i='car_names', j='year')

Example 2: Passing multiple ‘i’ parameter
In the following example, the dataframe used is the same as that used in the first example. But this time, we’ll pass the i parameter to the Python wide_to_long function.
pd.wide_to_long(df, stubnames='jan', i=['car_names','fuel_type'], j='year')

Example 3: Passing the ‘sep’ parameter
Let’s now change the dataframe and pass the sep parameter to the Python wide_to_long function and see how it affects the output
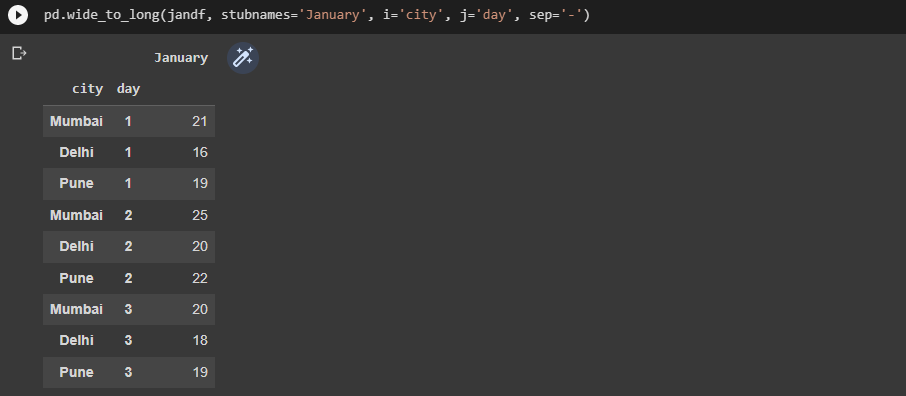
jandf = pd.DataFrame({"city": ['Mumbai','Delhi','Pune'],
"January-1": [21, 16, 19],
"January-2": [25, 20, 22],
"January-3": [20, 18, 19]})
print(jandf)

pd.wide_to_long(jandf, stubnames='January', i='city', j='day', sep='-')
Summary
In conclusion, the Pandas package helps to work on huge datasets. The function discussed in this article helps to restructure the DataFrame by turning many columns into many rows format. This helps the user to increase readability in certain cases.
To learn from more such detailed articles on various topics related to Python programming language as well as the Pandas package do click here.
Reference



