🚀 Supercharge your YouTube channel's growth with AI.
Try YTGrowAI FreeData Scaling in Python | Standardization and Normalization

We have already read a story on data preprocessing. In that, i.e. data preprocessing, data transformation, or scaling is one of the most crucial steps. You may be thinking about its importance, it is because, whenever you work with data, it includes multiple variables and values in different scales.
Data Scaling in Python
For an algorithm, to perform at its best, the data should be on the same scale. When it comes to data scaling in python, we got two key techniques – Standardization and Normalization.
In this story, let’s see how standardization and normalization techniques can be applied to the data in our hands.
Import the Data
We are going to use the Cruise ship dataset for this whole process. Let’s import the data and try applying above mentioned scaling techniques to it.
#Data
import pandas as pd
data = pd.read_csv('cruise_ship_data.csv')

we have imported the cruise ship dataset. Let’s see some of the basic stats of the data to it better.
#Data shape
data.shape
(158, 9)
- Our data contains 158 rows and 9 variables.
#data columns
data.columns
Index([‘Ship_name’, ‘Cruise_line’, ‘Age’, ‘Tonnage’, ‘passengers’, ‘length’, ‘cabins’, ‘passenger_density’, ‘crew’], dtype=’object’)
- This is the list of variables in the data.
#summary statistics
data.describe()

- Summary statistics of the Cruise Ship data.
By using summary statistics we can see the range or scale of values of all the features. For example, from the above data, we can see that the values in variable “Age” lie between [ 4, 48] and values in variable “Crew” in between [0, 21] and so on. You can observe that all the attributes have values on a different scale.
So, we need to scale the data using data transformation techniques such as Data standardization and Normalization. Let’s see how we can do that.
1. Python Data Scaling – Standardization
Data standardization is the process where using which we bring all the data under the same scale. This will help us to analyze and feed the data to the models.

This is the math behind the process of data standardization.
Before we compute the standardized values for the data, we need to install the sklearn library. You can run the below code to pip install the scikit-learn library.
#install scikit learn
pip install scikit-learn
#import pandas
import pandas as pd
#import numpy
import numpy as np
#import seaborn
import seaborn as sns
#import matplotplib
import matplotlib.pyplot as plt
Well, we are all good with our libraries. Now, let’s standardize the values in the data. For this, we will follow a process or some steps.
#define the columns
cols = ['Age', 'Tonnage', 'passengers', 'length',
'cabins','passenger_density','crew']
#Call the sklearn librart and import scaler values
from sklearn.preprocessing import StandardScaler
#call the standard scaler
std_scaler = StandardScaler()
#fit the values to the function
Stand_Sc = std_scaler.fit_transform(data[cols].iloc[:,range(0,7)].values)
#use seaborn for KDE plot
sns.kdeplot(Stand_Sc[:,5],fill=True, color = 'Green')
#Label the plot
plt.xlabel('standardized values - Passenger density')
#Print the plot
plt.show()
Here –
- we have defined the columns and Imported the standard scaler from the sklearn library.
- We fitted the data (defined cols) to the scaler.
- Created a KDE (Kernel Density Estimation) plot.
- Labelled the axis of the plot. The output plot will look like –

Inference
If we take the approximation value, the data lies between the scale of -3 to 3. You can also say that the values lie 3 standard deviations away from the mean ( 0 ).
2. Python Data Scaling – Normalization
Data normalization is the process of normalizing data i.e. by avoiding the skewness of the data. Generally, the normalized data will be in a bell-shaped curve.
It is also a standard process to maintain data quality and maintainability as well. Data normalization helps in the segmentation process.
The below is the Normalization formula for your reference.
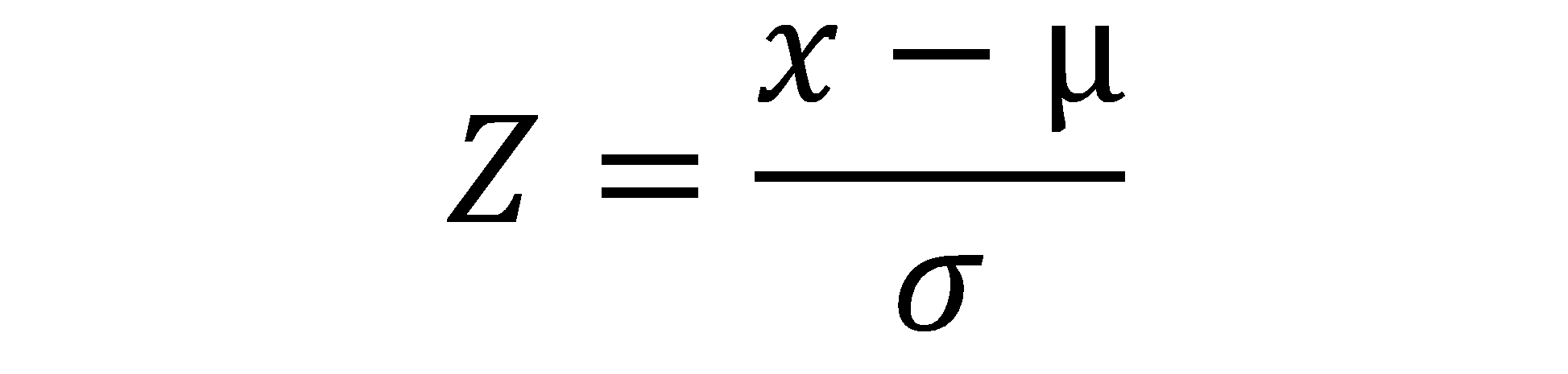
In the above section, we have standardized the data. Similarly, using the sklearn Normalizer, we can normalize the values in the data.
Make sure you keep the columns as same as the previous.
#Import Normalizer from sklearn
from sklearn.preprocessing import Normalizer
#initialize normalizer
data_norm = Normalizer()
#Fit the data
Normalize = data_norm.fit_transform(data[cols].iloc[:,range(0,7)].values)
#Distribution plot
sns.displot(Normalize[:,5],fill=True, color = 'orange')
#Add the axis labels
plt.xlabel('normalized values - passenger density')
#Display the plot
plt.show()
Here –
- We have used the same data i.e. variables for the normalization process.
- Imported the Normalizer from the sklearn library.
- Plot the distribution plot using seaborn and display plot.

We can also add the KDE element to this plot. It will add more readability and it will be much easier to digest the information.
This can be done by adding the argument – kde = True
#Import Normalizer from sklearn
from sklearn.preprocessing import Normalizer
#initialize normalizer
data_norm = Normalizer()
#Fit the data
Normalize = data_norm.fit_transform(data[cols].iloc[:,range(0,7)].values)
#Distribution plot
#sns.displot(Normalize[:,5],fill=True, color = 'orange')
sns.displot(Normalize[:,5],fill=True, color = 'orange', kde=True)
#Add the axis labels
plt.xlabel('normalized values - passenger density')
#Display the plot
plt.show()

Inference –
Here, you can observe that the values are on a scale of -1 to 1.
Data Scaling – Key Points
- Data standardization is the most commonly used process as it offers multiple benefits.
- You can use Standardization for outlier detection as well. Any values lies outside range -2 to 2 can be considered as outliers.
- Finally, data transformation helps to avoid bias and increase model accuracy.
Data Scaling – Conclusion
Data scaling in python is an essential process to follow before modeling. The Data within a similar scale can surprisingly increase the model’s predictive power. This story focuses on two major data scaling techniques i.e. Standardization and Normalization. I hope this will help to understand the scaling better and in an easy way.
That’s all for now. Happy Python!!! 😛
More read: Normalization of data



