🚀 Supercharge your YouTube channel's growth with AI.
Try YTGrowAI FreeHTMLParser in Python 3.x
html.parser.HTMLParser provides a very simple and efficient way for coders to read through HTML code. This library comes pre-installed in the stdlib. This simplifies our interfacing with the HTMLParser library as we do not need to install additional packages from the Python Package Index (PyPI) for the same task.
What is HTMLParser?
Essentially, HTMLParser lets us understand HTML code in a nested fashion. The module has methods that are automatically called when specific HTML elements are met with. It simplifies HTML tags and data identification.
When fed with HTML data, the tag reads through it one tag at a time, going from start tags to the tags within, then the end tags and so on.
How to Use HTMLParser?
HTMLParser only identifies the tags or data for us but does not output any data when something is identified. We need to add functionality to the methods before they can output the information they find.
But if we need to add functionality, what’s the use of the HTMLParser? This module saves us the time of creating the functionality of identifying tags ourselves.
We’re not going to code how to identify the tags, only what to do once they’re identified.
Understood? Great! Now let’s get into creating a parser for ourselves!
Subclassing the HTMLParser
How can we add functionality to the HTMLParser methods? By subclassing. Also identified as Inheritance, we create a class that retains the behavior of HTMLParser, while adding more functionality.
Subclassing lets us override the default functionality of a method (which in our case, is to return nothing when tags are identified) and add some better functions instead. Let’s see how to work with the HTMLParser now.
Finding Names of The Called Methods
There are many methods available within the module. We’ll go over the ones you’d need frequently and then learn how to make use of them.
- HTMLParser.handle_starttag(tag, attrs) – Called when start tags are found (example <html>, <head>, <body>)
- HTMLParser.handle_endtag(tag) – Called when end tags are found (example <html/>, <head/>, <body/>)
- HTMLParser.handle_data(data) – Called when data is found (example <a href =#> data </a>)
- HTMLParser.handle_comment(data) – Called when comments are found (example <!–This is a comment–>)
- HTMLParser.handle_decl(decl) – Called when declarations are found (example <!DOCTYPE html>)
Creating Your HTMLParser
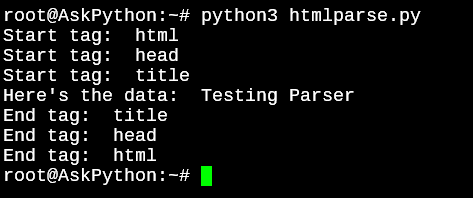
Let’s define basic print functionalities to the methods in the HTMLParser module. In the below example, all I’m doing is adding a print method whenever the method is called.
The last line in the code is where we feed data to the parser. I fed basic HTML code directly, but you can do the same by using the urllib module to directly import a website into python too.
from html.parser import HTMLParser
class Parse(HTMLParser):
def __init__(self):
#Since Python 3, we need to call the __init__() function
#of the parent class
super().__init__()
self.reset()
#Defining what the methods should output when called by HTMLParser.
def handle_starttag(self, tag, attrs):
print("Start tag: ", tag)
for a in attrs:
print("Attributes of the tag: ", a)
def handle_data(self, data):
print("Here's the data: ", data)
def handle_endtag(self, tag):
print("End tag: ", tag)
testParser = Parse()
testParser.feed("<html><head><title>Testing Parser</title></head></html>")
What Can HTMLParser Be Used For?
Web data scraping.
This is what most people would need the HTMLParser module for. Not to say that it cannot be used for anything else, but when you need to read loads of websites and find specific information, this module will make the task a cakewalk for you.
HTMLParser Real World Example
I’m going to pull every single link from the Python Wikipedia page for this example.
Doing it manually, by right-clicking on a link, copying and pasting it in a word file, and then moving on to the next is possible too. But that would take hours if there are lots of links on the page which is a typical situation with Wikipedia pages.
But we’ll be spending 5 minutes to code an HTMLParser and get the time needed to finish the task from hours to a few seconds. Let’s do it!
from html.parser import HTMLParser
import urllib.request
#Import HTML from a URL
url = urllib.request.urlopen("https://en.wikipedia.org/wiki/Python_(programming_language)")
html = url.read().decode()
url.close()
class Parse(HTMLParser):
def __init__(self):
#Since Python 3, we need to call the __init__() function of the parent class
super().__init__()
self.reset()
#Defining what the method should output when called by HTMLParser.
def handle_starttag(self, tag, attrs):
# Only parse the 'anchor' tag.
if tag == "a":
for name,link in attrs:
if name == "href" and link.startswith("http"):
print (link)
p = Parse()
p.feed(html)

The Python programming page on Wikipedia has more than 300 links. I’m sure it would have taken me at least an hour to make sure we had all of them. But with this simple script, it took <5 seconds to output every single link without missing any of them!
Conclusion
This module is really fun to play around with. We ended up scraping tons of data from the web using this simple module in the process of writing this tutorial.
Now there are other modules like BeautifulSoup which are more well known. But for quick and simple tasks, HTMLParser does a really amazing job!



